Android的Handler机制
首先放一张流程图:
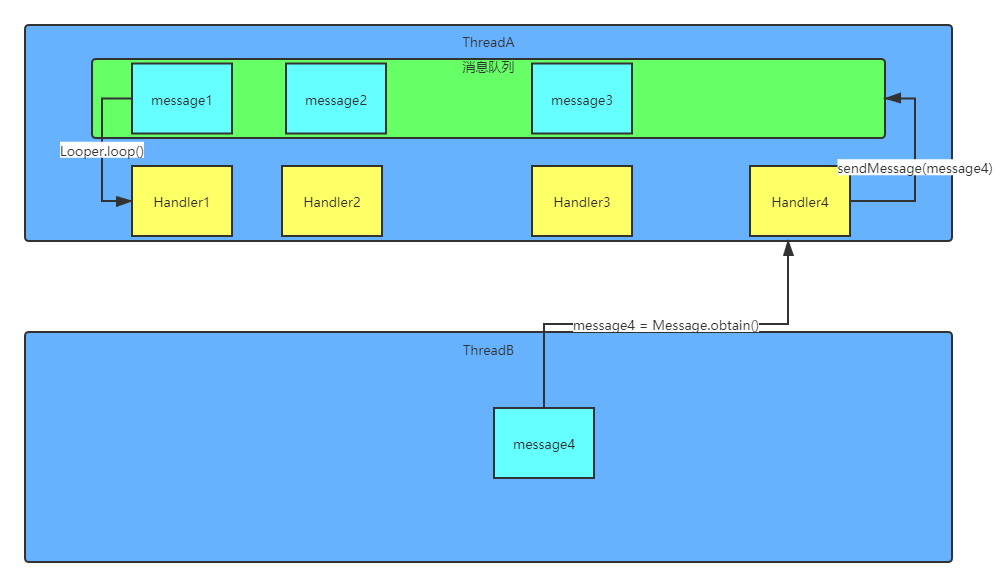
上面这张流程图主要涉及了Handler通讯的四个组成部分: Handler、Message、Looper、MessageQueue, 下面我们就从message4的传递过程来解释Handler的机制.
Message
从图中可以看到, 在创建message4实例的时候, 我们并没有调用构造函数, 而是使用了一个类方法. 这是为什么呢?我们看一下源码:
1 | private static final Object sPoolSync = new Object(); |
源码还是比较好懂的, 简单来说, Message使用了一个消息池来循环利用这些message, 如果在申请message的时候池子里没有了, 才会新创建一个message. 当然, 我们也可以主动调用Message的构造函数.
Handler
message创建完后, 就要调用handler的sendMessage函数了. 不过在调用之前, 我们肯定得先创建一个handler对吧?那我们就得先看看handler的构造函数了:
1 | public Handler(Callback call) { |
函数很长, 所以这里只放出了一部分. 这部分非常重要, 无论是参数call还是handler保留的Looper和消息队列的引用都是一个大的伏笔, 我们下面会提到.
现在我们再看一下sendMessage源码:
1 | public boolean sendMessageAtTime(Message msg, long uptimeMillis) { |
sendMessage和sendMessageAtTime逻辑一样, 所以我们这么也可以看(实际上是因为我从源码那里拿错了……). 其实这个函数并没有多少内容, 除了出错处理外, 实际上还是执行了enqueueMessage这个函数, 那么我们再看一看这个函数的源码:
1 | private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) { |
看起来好像还是没写啥, 因为抛去异步处理, 其实还是调用了MessageQueue的enqueueMessage函数. 但是其实这里埋了一个伏笔. 我们关注一下第一行的赋值: message4持有了handler4的一个引用. 明明是handler4对message4进行处理呀, 为什么message4持有handler4的引用呢?先按下不表, 我们再往下看消息队列.
MessageQueue
在看消息队列的源码之前, 我们先看一下图: ThreadA有一个消息队列, 而ThreadB没有. 没错, 消息队列不是每一个线程都有的. 在默认情况下, 只有负责UI的主线程会拥有一个消息队列. 不过我们也可以人为的给一个线程创建一个消息队列, 至于怎么创建, 我们下面会提到.
然后我们再说一下消息队列的性质. 既然它的名字叫做消息队列, 那么肯定就符合先进先出的性质了. 放在Message的这个情境下, 就是说消息队列按照message创建的先后顺序管理它们, 旧的message先出队被处理, 新的message后出队被处理. 而我们都知道, 队列一般都是由数组或者链表实现的, 像消息队列这种单元很抽象的队列, 自然应该是用链表实现.
现在我们可以看源码了:
1 | boolean enqueueMessage(Message msg, |
由于这个函数很长很长, 所以我只放出了相关的部分, 同时为了方便大家看, 我做了点注释. 这样大家可以看到, handler的sendMessage函数实际上就是把message放到了handler在构造时绑定的消息队列中, 就像图上那样.
Looper
光是把message入队可不行, 还必须要有出队的操作. Looper就是实现这个功能的. 关于Looper, 我们主要用到Looper.prepare和Looper.loop两个函数. 我们先看一下prepare函数:
1 | private Looper(boolean quitAllowed) { |
我们看到, Looper在被创建时, 会一同创建消息队列, 同时保有创造线程的引用. 再结合prepare函数中的出错处理, 我们就可以知道Looper和消息队列与线程的关系了: 除了用于更新UI的主线程, 其它线程默认是没有Looper和消息队列的, 但是我们可以人为为线程创建Looper, Looper在创建的过程中会主动创建一个消息队列. 对于一个线程来说, 它的Looper和消息队列是唯一的. 如果在拥有Looper和消息队列的情况下再调用Looper.prepare, 系统就会报错.
为什么Looper和消息队列是绑定的呢?答案在Looper.loop函数里:
1 | public static void loop() { |
除去各种报错函数, 其实loop函数的逻辑很简单: 一个不断执行Message msg = queue.next()、msg.target.dispatchMessage(msg)、msg.recycleUnchecked()的死循环.
Message msg = queue.next()很好理解, 就是从队列中拿出了队首的Message.
msg.recycleUnchecked()也很好理解, 用完message后就将其放回消息池内.
那么msg.target.dispatchMessage(msg)怎么理解?这就是Message要保留handler引用的原因. 我们看一下dispatchMessage函数的源码:
1 | /** |
dispatchMessage函数根据情况提供了三种方式处理message. 第一种是通过handler的post函数创造一个包含方法回调的message(至于什么是方法回调, 以后我们再说); 第二种是通过Handler(Callback)的构造函数在创建handler时就把回调函数放进去, message仅仅是通知handler执行该方法的信号; 第三种就是我们常用的重写handlerMessage函数.
总结
写到这里, Handler的机制就已经说完了. 因为设计到源码的展示, 所以我只想到了上面的这种解说方式, 可能这样还是很难在脑海中构建出一个模型. 不过当大家看到这里的时候, 上面的内容也大概都有印象了, 在这里就再用文字概括一下Handler的机制:
每个线程最多只能有一个消息队列和一个Looper, 除了主线程之外, 其他线程都需要通过Looper.prepare()创建消息队列和Looper.
Handler在创建时就会与创建它的线程的Looper和消息队列绑定. 在执行sendMessage时, handler会把message放到它绑定的消息队列的队尾. 这个时候handler不会执行处理message的方法.
Looper就像一个引擎, 不断地通过Looper.loop将消息队列的消息取出并分发到message对应的handler那里. 这也就是我们说Android是事件驱动的的原因.
handler在从Looper那里拿到分发的message后, 才会执行相应的处理函数. 处理函数一共分三种. 第一种是通过handler的post函数创建一个message, message既是通知handler执行处理函数的信号, 也是运输处理函数的载体; 第二种是将执行函数直接写入handler中, message仅作为通知handler执行的信号; 第三种是重写handler的handlerMessage函数, message既是信号, 也传输了简单的函数参数.
请大家参考上面的四点, 再对照文章开始的图片, 应该就不难理解了.